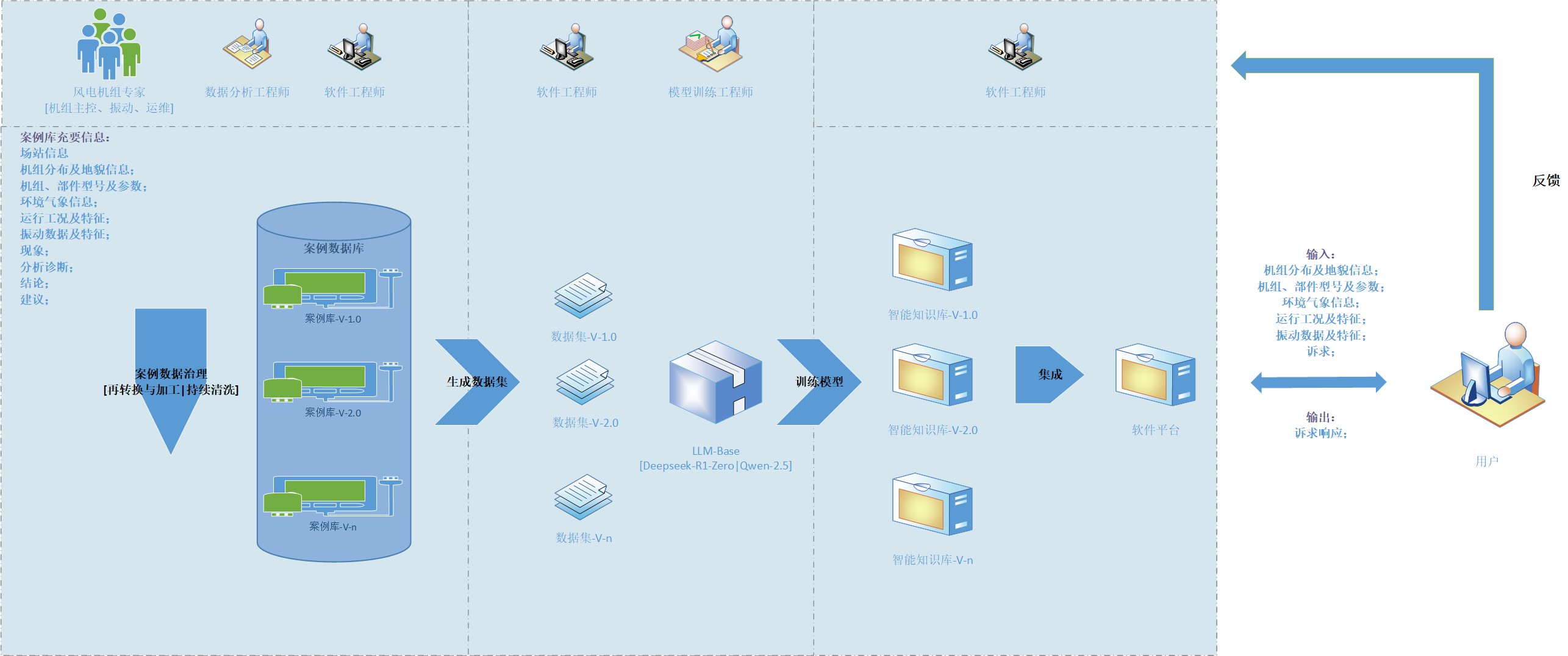
|
|
@@ -1,10 +1,999 @@
|
|
|
+# 人工智能知识库建设-风电机组故障与发电性能异常知识库
|
|
|
+
|
|
|
+<div align=center><img src="./resources/images/人工智能知识库-电力行业风力发电领域.png"></div>
|
|
|
+
|
|
|
+# 大语言模型介绍
|
|
|
+## 基础概念
|
|
|
+
|
|
|
+### 蒸馏
|
|
|
+在机器学习的语境中,**蒸馏(Knowledge Distillation)** 是一种模型压缩技术,其核心思想是将一个复杂的大模型(称为**教师模型**)中的“知识”迁移到一个更轻量的小模型(称为**学生模型**)中,使得小模型能以更低的计算成本实现接近甚至超越原大模型的性能。
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+#### **蒸馏的核心含义**
|
|
|
+1. **知识迁移**
|
|
|
+ 教师模型的“知识”不仅指其参数,更包括:
|
|
|
+ - **输出层知识**:模型对输入数据的预测概率分布(软标签,Soft Labels)。
|
|
|
+ - **中间层知识**:隐藏层的特征表示(如注意力权重、激活值)。
|
|
|
+ - **推理逻辑**:复杂任务的解题步骤或生成策略(如代码生成、数学推导)。
|
|
|
+
|
|
|
+2. **训练方式**
|
|
|
+ 学生模型通过以下方式学习教师模型的知识:
|
|
|
+ - **模仿输出**:在训练时,学生模型不仅学习真实标签(硬标签),还学习教师模型输出的概率分布(软标签),后者包含更丰富的类别间关系信息。
|
|
|
+ *例如:教师模型判断“猫”的概率为0.8,“狗”为0.15,“狐狸”为0.05,学生模型会学习这种更细粒度的概率分布。*
|
|
|
+ - **特征对齐**:通过匹配教师模型和学生模型的中间层特征(如隐藏状态),强制学生模型学习相似的内部表征。
|
|
|
+
|
|
|
+3. **目的**
|
|
|
+ - **压缩模型**:将大模型(如千亿参数)压缩为小模型(如百亿参数),便于部署到资源受限的环境(手机、嵌入式设备等)。
|
|
|
+ - **提升效率**:减少推理时的计算量和内存占用,同时保持高性能。
|
|
|
+ - **知识泛化**:通过教师模型的指导,学生模型可能泛化到未见过的新任务或数据。
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+#### **蒸馏 vs 传统训练**
|
|
|
+| **对比维度** | **传统训练** | **知识蒸馏** |
|
|
|
+|--------------------|---------------------------|---------------------------------|
|
|
|
+| **训练目标** | 直接拟合真实标签(硬标签) | 同时拟合真实标签 + 教师模型的软标签 |
|
|
|
+| **知识来源** | 仅训练数据 | 训练数据 + 教师模型的隐性知识 |
|
|
|
+| **模型复杂度** | 学生模型独立训练 | 学生模型受教师模型指导 |
|
|
|
+| **效果** | 依赖数据量和模型容量 | 小模型可逼近大模型性能 |
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+#### **蒸馏的典型应用场景**
|
|
|
+1. **模型轻量化**:将 GPT-4、Qwen-72B 等超大模型压缩为适合手机或边缘设备的版本(如 DeepSeek-R1)。
|
|
|
+2. **加速推理**:减少服务端模型的响应延迟和计算成本。
|
|
|
+3. **隐私保护**:用蒸馏模型替代原始大模型,避免敏感数据直接输入大模型。
|
|
|
+4. **领域适配**:通过教师模型的领域知识(如医疗、法律),快速训练专用小模型。
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+#### **DeepSeek-R1 中的蒸馏意义**
|
|
|
+在 DeepSeek-R1-Distill-Qwen-32B 中,蒸馏技术可能用于:
|
|
|
+- 将 Qwen 系列大模型的复杂能力(如代码生成、多轮对话)迁移到更小的模型架构中。
|
|
|
+- 通过软标签和中间层对齐,保留原模型的逻辑推理和泛化能力。
|
|
|
+- 实现低资源环境下的高效部署(如企业级私有化部署)。
|
|
|
+
|
|
|
+简而言之,**蒸馏是通过“师生传承”让轻量模型继承重量级模型智慧的技术**,是平衡性能与效率的关键手段。
|
|
|
+
|
|
|
+**示例:**
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+DeepSeek-R1-Distill-Qwen-32B 是基于知识蒸馏技术对原模型(如 Qwen-32B 或其他大规模模型)进行优化的产物。虽然具体细节需以官方文档为准,但根据知识蒸馏的常见方法和模型优化目标,可以推测其蒸馏内容可能包括以下方面:
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+#### 1. **模型架构精简**
|
|
|
+ - **参数压缩**:通过减少模型层数、隐藏层维度或注意力头数,降低参数量(如从千亿级压缩到百亿级)。
|
|
|
+ - **结构简化**:移除冗余模块或替换为更高效的组件(如简化注意力机制)。
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+#### 2. **知识迁移策略**
|
|
|
+ - **输出层蒸馏(Logits Distillation)**:对齐学生模型与教师模型的输出概率分布(软标签),保留语义理解和生成能力。
|
|
|
+ - **中间层特征匹配**:通过匹配教师模型和学生模型的中间层特征(如注意力权重、隐藏状态),提升学生模型的表征能力。
|
|
|
+ - **多任务蒸馏**:在通用文本生成、代码理解、数学推理等多任务上迁移教师模型的能力。
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+#### 3. **训练数据优化**
|
|
|
+ - **合成数据增强**:利用教师模型生成高质量合成数据(如问答对、解题步骤),补充训练集。
|
|
|
+ - **数据筛选**:基于教师模型的置信度或复杂度评分,筛选高质量、多样化的训练样本。
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+#### 4. **推理效率提升**
|
|
|
+ - **计算加速**:通过降低计算精度(如 FP16 量化)、优化矩阵运算,减少推理延迟。
|
|
|
+ - **内存优化**:采用动态内存管理或缓存策略,降低显存占用。
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+#### 5. **领域知识保留**
|
|
|
+ - **垂直领域适配**:针对代码生成、数学推理、多语言理解等场景,保留教师模型的领域专精能力。
|
|
|
+ - **少样本学习**:通过蒸馏增强模型在少样本或零样本任务中的泛化性。
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+#### 6. **训练策略改进**
|
|
|
+ - **渐进式蒸馏**:分阶段迁移知识(如先通用能力后领域能力),避免性能损失。
|
|
|
+ - **对抗训练**:引入对抗样本提升鲁棒性,或结合强化学习优化生成质量。
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+#### 7. **模型对齐与安全**
|
|
|
+ - **价值观对齐**:通过蒸馏传递符合伦理的内容生成约束,减少有害输出。
|
|
|
+ - **安全护栏(Safety Guardrails)**:继承教师模型的安全过滤机制,增强可控性。
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+#### 典型应用场景(推测)
|
|
|
+- **端侧部署**:优化后的模型可能适用于边缘设备或低资源环境。
|
|
|
+- **低成本推理**:减少云计算依赖,适合大规模商业化应用。
|
|
|
+- **多任务服务**:保留原模型的多领域能力,支持问答、代码、数学等综合场景。
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+如需更准确的信息,建议参考深度求索(DeepSeek)的官方技术报告或开源文档,以获取蒸馏方法、实验对比等细节。
|
|
|
+
|
|
|
+
|
|
|
+## 1. **Timer**
|
|
|
+ - **含义**:Timer 是一种用于优化模型推理效率的技术,通常用于减少模型的计算时间或延迟。
|
|
|
+ - **核心思想**:
|
|
|
+ - 通过动态调整模型的计算资源(如跳过某些层或模块),在保证性能的同时加速推理。
|
|
|
+ - 适用于实时性要求高的场景(如对话系统、推荐系统)。
|
|
|
+ - **应用场景**:
|
|
|
+ - 减少大模型的推理延迟。
|
|
|
+ - 在边缘设备上部署轻量级模型。
|
|
|
+ - **示例**:
|
|
|
+ - 在 Transformer 模型中,根据输入复杂度动态跳过某些注意力头或层。
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+## 2. **COT(Chain-of-Thought)**
|
|
|
+ - **含义**:COT 是一种提示(Prompting)技术,通过引导模型生成中间推理步骤,提升复杂任务(如数学推理、逻辑推理)的性能。
|
|
|
+ - **核心思想**:
|
|
|
+ - 让模型像人类一样“逐步思考”,生成中间推理过程,而不是直接输出最终答案。
|
|
|
+ - 特别适合需要多步推理的任务。
|
|
|
+ - **应用场景**:
|
|
|
+ - 数学问题求解。
|
|
|
+ - 逻辑推理任务。
|
|
|
+ - 复杂问答系统。
|
|
|
+ - **示例**:
|
|
|
+ - 输入:“如果小明有5个苹果,吃了2个,又买了3个,他现在有多少个苹果?”
|
|
|
+ - 模型输出:“小明原来有5个苹果,吃了2个,剩下3个。又买了3个,所以现在有6个苹果。”
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+## 3. **RAG(Retrieval-Augmented Generation)**
|
|
|
+ - **含义**:RAG 是一种结合检索(Retrieval)和生成(Generation)的技术,通过从外部知识库中检索相关信息来增强生成模型的能力。
|
|
|
+ - **核心思想**:
|
|
|
+ - 在生成答案之前,先从大规模知识库(如维基百科)中检索相关文档或段落。
|
|
|
+ - 将检索到的信息与输入问题结合,生成更准确、可靠的答案。
|
|
|
+ - **应用场景**:
|
|
|
+ - 开放域问答(Open-Domain QA)。
|
|
|
+ - 知识密集型任务(如事实核查、文档生成)。
|
|
|
+ - **示例**:
|
|
|
+ - 输入:“谁发明了电话?”
|
|
|
+ - 模型检索到相关文档:“电话是由亚历山大·格拉汉姆·贝尔发明的。”
|
|
|
+ - 模型生成答案:“电话是由亚历山大·格拉汉姆·贝尔发明的。”
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+## 4. **Fine-tuning(微调)**
|
|
|
+ - **含义**:Fine-tuning 是一种迁移学习技术,通过在大规模预训练模型的基础上,使用特定任务的数据进行进一步训练,使模型适应特定任务。
|
|
|
+ - **核心思想**:
|
|
|
+ - 预训练模型(如 GPT、BERT)在大规模通用数据上学习通用语言表示。
|
|
|
+ - 微调阶段使用特定任务的数据(如情感分类、命名实体识别)调整模型参数,使其在特定任务上表现更好。
|
|
|
+ - **应用场景**:
|
|
|
+ - 领域适配(如医疗、法律)。
|
|
|
+ - 特定任务优化(如文本分类、机器翻译)。
|
|
|
+ - **示例**:
|
|
|
+ - 使用 BERT 模型在情感分析数据集(如 IMDb)上进行微调,用于电影评论的情感分类。
|
|
|
+
|
|
|
+**技术对比**
|
|
|
+| **技术** | **目标** | **核心方法** | **典型应用场景** |
|
|
|
+|----------------|-----------------------------------|------------------------------------------|----------------------------------|
|
|
|
+| **Timer** | 优化推理效率 | 动态调整计算资源 | 实时对话、边缘计算 |
|
|
|
+| **COT** | 提升复杂任务推理能力 | 生成中间推理步骤 | 数学推理、逻辑推理 |
|
|
|
+| **RAG** | 增强生成模型的准确性 | 结合检索和生成 | 开放域问答、知识密集型任务 |
|
|
|
+| **Fine-tuning**| 适应特定任务 | 在预训练模型基础上进行任务特定训练 | 领域适配、文本分类 |
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+**结合使用示例**
|
|
|
+- **RAG + COT**:在开放域问答中,先检索相关知识,再通过 Chain-of-Thought 生成推理步骤和最终答案。
|
|
|
+- **Fine-tuning + Timer**:在特定领域(如医疗)微调模型后,使用 Timer 技术优化推理效率,便于实时应用。
|
|
|
+
|
|
|
+这些技术各有侧重,但可以结合使用,以构建更强大、高效的 NLP 系统。
|
|
|
+
|
|
|
+
|
|
|
+## 架构
|
|
|
+ MoE(Mixture of Experts)架构
|
|
|
+ 一、原理
|
|
|
+ 专家模块
|
|
|
+ MoE由多个“专家”(expert)组成。这些专家通常是一些较小的神经网络,例如多层感知机(MLP)。每个专家都有自己独特的参数和处理能力。
|
|
|
+ 门控机制
|
|
|
+ 伴随专家模块的是一个门控网络。当输入数据到来时,门控网络会根据输入的特征决定将该输入路由到哪个专家或者哪些专家的组合上进行处理。这种路由决策是基于数据驱动的,旨在把不同类型的输入分配给最适合处理它们的专家。
|
|
|
+ 二、优点
|
|
|
+ 高效性
|
|
|
+ 在处理大规模数据和复杂任务时,可以有效地利用计算资源。因为不必让所有的数据都通过一个庞大而统一的模型,而是将不同部分的数据分发给擅长处理它们的专家,从而避免了在一些不相关任务上浪费计算资源。
|
|
|
+ 模型容量大
|
|
|
+ 通过组合多个专家,可以增加模型整体的容量。这意味着它能够学习到更多的模式和关系,对于复杂任务有更好的表现能力。
|
|
|
+ 三、缺点
|
|
|
+ 训练复杂性
|
|
|
+ 需要仔细地设计门控机制,确保正确的输入被路由到合适的专家。不当的路由可能导致某些专家被过度使用,而其他专家则未得到充分利用,影响模型性能。而且训练过程中需要平衡各个专家之间的权重更新等问题。
|
|
|
+ 通信开销
|
|
|
+ 在分布式训练的情况下,如果多个专家分布在不同的计算设备上,数据在设备之间的路由会带来一定的通信开销,这可能会影响训练速度和效率。
|
|
|
+ Dense(密集连接)架构
|
|
|
+ 一、原理
|
|
|
+ 全连接特性
|
|
|
+ 在Dense架构的神经网络中,每一层的神经元都与它之前的所有层中的神经元相连。例如,在一个简单的三层神经网络中,第二层的每个神经元都接收来自第一层所有神经元的输入,第三层的每个神经元又接收来自第一和第二层所有神经元的输入。
|
|
|
+ 特征重复利用
|
|
|
+ 由于这种全连接的方式,前面层提取的特征可以被后续层多次利用。这有助于深度神经网络逐步从原始数据中学习到更高级、更抽象的特征表示。
|
|
|
+ 二、优点
|
|
|
+ 信息传递完全
|
|
|
+ 保证了信息在网络中的最大程度流动。前面层的任何微小变化都能传播到后面的所有层,使得模型能够充分利用输入数据中的所有信息,有利于学习复杂的函数映射。
|
|
|
+ 特征学习深度
|
|
|
+ 能够深入挖掘数据中的特征。随着网络层数的增加,它可以不断地在前序特征基础上构建新的特征,适合处理一些具有高度非线性关系的任务,如图像识别、自然语言处理中的语义理解等。
|
|
|
+ 三、缺点
|
|
|
+ 参数量大
|
|
|
+ 由于每层都与之前所有层全连接,当网络层数增加和输入维度增大时,模型的参数数量会急剧增加。这不仅会导致训练时间长,还容易产生过拟合现象,尤其在数据量相对较小时更为明显。
|
|
|
+ 计算复杂度高
|
|
|
+ 在计算每一层的输出时,由于大量的连接,需要进行大量的乘法和加法运算,这对计算资源(如GPU内存和计算速度)提出了很高的要求,限制了模型在一些计算资源有限设备上的应用。
|
|
|
+
|
|
|
+## Deepseek-R1
|
|
|
+
|
|
|
+在 **DeepSeek-R1** 模型中,**SFT** 和 **GRPO** 是两种重要的技术或方法,分别用于模型训练和优化。以下是它们的详细介绍:
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+### 1. **SFT(Supervised Fine-Tuning,监督微调)**
|
|
|
+
|
|
|
+#### **定义**
|
|
|
+SFT 是一种通过使用标注数据对预训练模型进行微调的技术。它通常在预训练模型的基础上,针对特定任务(如文本分类、问答等)进行进一步训练。
|
|
|
+
|
|
|
+#### **作用**
|
|
|
+- **任务适配**:将通用预训练模型适配到特定任务。
|
|
|
+- **性能提升**:通过微调,模型在特定任务上的性能会显著提升。
|
|
|
+
|
|
|
+#### **实现步骤**
|
|
|
+1. **准备标注数据**:
|
|
|
+ - 收集与任务相关的标注数据(如输入-输出对)。
|
|
|
+2. **加载预训练模型**:
|
|
|
+ - 加载 DeepSeek-R1 的预训练模型。
|
|
|
+3. **微调模型**:
|
|
|
+ - 在标注数据上训练模型,通常使用交叉熵损失等监督学习目标函数。
|
|
|
+4. **评估模型**:
|
|
|
+ - 在验证集上评估微调后的模型性能。
|
|
|
+
|
|
|
+#### **代码示例**
|
|
|
+```python
|
|
|
+from transformers import AutoModelForSequenceClassification, AutoTokenizer, Trainer, TrainingArguments
|
|
|
+from datasets import load_dataset
|
|
|
+
|
|
|
+# 加载预训练模型和分词器
|
|
|
+model = AutoModelForSequenceClassification.from_pretrained("deepseek-r1")
|
|
|
+tokenizer = AutoTokenizer.from_pretrained("deepseek-r1")
|
|
|
+
|
|
|
+# 加载数据集
|
|
|
+dataset = load_dataset("your_dataset")
|
|
|
+
|
|
|
+# 数据预处理
|
|
|
+def preprocess_function(examples):
|
|
|
+ return tokenizer(examples["text"], truncation=True, padding="max_length")
|
|
|
+
|
|
|
+tokenized_datasets = dataset.map(preprocess_function, batched=True)
|
|
|
+
|
|
|
+# 定义训练参数
|
|
|
+training_args = TrainingArguments(
|
|
|
+ output_dir="./results",
|
|
|
+ evaluation_strategy="epoch",
|
|
|
+ learning_rate=2e-5,
|
|
|
+ per_device_train_batch_size=16,
|
|
|
+ num_train_epochs=3,
|
|
|
+ weight_decay=0.01,
|
|
|
+)
|
|
|
+
|
|
|
+# 定义 Trainer
|
|
|
+trainer = Trainer(
|
|
|
+ model=model,
|
|
|
+ args=training_args,
|
|
|
+ train_dataset=tokenized_datasets["train"],
|
|
|
+ eval_dataset=tokenized_datasets["validation"],
|
|
|
+)
|
|
|
+
|
|
|
+# 微调模型
|
|
|
+trainer.train()
|
|
|
+```
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+### 2. **GRPO(Group Relative Policy Optimization,组相对策略优化)**
|
|
|
+
|
|
|
+关于 **DeepSeek 的 GRPO(Group Relative Policy Optimization)**,目前公开的技术细节有限(截至2023年10月,DeepSeek 尚未发布官方论文或完整代码)。但根据命名推测,GRPO 可能是一种**基于分组的相对策略优化方法**,结合了强化学习(RL)中的策略优化思想,并引入“分组”与“相对比较”机制以提升训练效率。以下是对其可能设计逻辑的推测及一个简化示例代码框架。
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+#### **GRPO 的核心概念(推测)**
|
|
|
+1. **分组(Grouping)**
|
|
|
+ - 将智能体的策略划分为多个组(例如不同策略参数或行为模式),通过组间交互或竞争提升探索效率。
|
|
|
+ - 可能应用场景:多智能体协作、策略多样性增强。
|
|
|
+
|
|
|
+2. **相对策略优化(Relative Policy Optimization)**
|
|
|
+ - 通过组间策略表现的**相对比较**(而非绝对奖励)调整策略参数,类似竞赛机制。
|
|
|
+ - 优势:减少对绝对奖励值的依赖,增强鲁棒性。
|
|
|
+
|
|
|
+3. **优化目标**
|
|
|
+ - 最大化组间相对优势,同时控制策略更新的稳定性(类似 PPO 的剪切机制)。
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+#### **示例代码框架(Python + PyTorch)**
|
|
|
+以下是一个简化的 GRPO 实现示例,基于单智能体环境(如 CartPole)的假设性设计:
|
|
|
+
|
|
|
+```python
|
|
|
+import torch
|
|
|
+import torch.nn as nn
|
|
|
+import torch.optim as optim
|
|
|
+from torch.distributions import Categorical
|
|
|
+import gym
|
|
|
+
|
|
|
+# 定义策略网络
|
|
|
+class Policy(nn.Module):
|
|
|
+ def __init__(self, state_dim, action_dim):
|
|
|
+ super().__init__()
|
|
|
+ self.fc = nn.Sequential(
|
|
|
+ nn.Linear(state_dim, 64),
|
|
|
+ nn.ReLU(),
|
|
|
+ nn.Linear(64, action_dim)
|
|
|
+ )
|
|
|
+
|
|
|
+ def forward(self, state):
|
|
|
+ return self.fc(state)
|
|
|
+
|
|
|
+# GRPO 算法核心
|
|
|
+class GRPO:
|
|
|
+ def __init__(self, state_dim, action_dim, n_groups=3, lr=1e-3, clip_epsilon=0.2):
|
|
|
+ self.n_groups = n_groups
|
|
|
+ self.policies = [Policy(state_dim, action_dim) for _ in range(n_groups)]
|
|
|
+ self.optimizers = [optim.Adam(policy.parameters(), lr=lr) for policy in self.policies]
|
|
|
+ self.clip_epsilon = clip_epsilon
|
|
|
+
|
|
|
+ def update(self, group_data):
|
|
|
+ # group_data: 每个组的轨迹数据 (states, actions, advantages)
|
|
|
+ for group_id in range(self.n_groups):
|
|
|
+ states, actions, advantages = group_data[group_id]
|
|
|
+ probs_old = Categorical(logits=self.policies[group_id](states)).log_prob(actions).detach()
|
|
|
+
|
|
|
+ # 计算当前策略概率
|
|
|
+ probs_new = Categorical(logits=self.policies[group_id](states)).log_prob(actions)
|
|
|
+
|
|
|
+ # 计算相对优势(假设其他组的平均优势为基线)
|
|
|
+ other_avg_advantage = torch.mean(torch.stack(
|
|
|
+ [torch.mean(adv) for adv in advantages if adv is not advantages]
|
|
|
+ ))
|
|
|
+ relative_advantages = advantages - other_avg_advantage
|
|
|
+
|
|
|
+ # 策略损失(类似 PPO 的剪切目标)
|
|
|
+ ratio = torch.exp(probs_new - probs_old)
|
|
|
+ clipped_ratio = torch.clamp(ratio, 1 - self.clip_epsilon, 1 + self.clip_epsilon)
|
|
|
+ loss = -torch.min(ratio * relative_advantages, clipped_ratio * relative_advantages).mean()
|
|
|
+
|
|
|
+ # 更新策略
|
|
|
+ self.optimizers[group_id].zero_grad()
|
|
|
+ loss.backward()
|
|
|
+ self.optimizers[group_id].step()
|
|
|
+
|
|
|
+# 训练循环(示例)
|
|
|
+env = gym.make('CartPole-v1')
|
|
|
+state_dim = env.observation_space.shape[0]
|
|
|
+action_dim = env.action_space.n
|
|
|
+grpo = GRPO(state_dim, action_dim, n_groups=3)
|
|
|
+
|
|
|
+for episode in range(1000):
|
|
|
+ group_data = {i: {"states": [], "actions": [], "advantages": []} for i in range(grpo.n_groups)}
|
|
|
+
|
|
|
+ # 并行收集各组轨迹数据
|
|
|
+ for group_id in range(grpo.n_groups):
|
|
|
+ state = env.reset()
|
|
|
+ done = False
|
|
|
+ while not done:
|
|
|
+ action_logits = grpo.policies[group_id](torch.FloatTensor(state))
|
|
|
+ action = Categorical(logits=action_logits).sample().item()
|
|
|
+ next_state, reward, done, _ = env.step(action)
|
|
|
+
|
|
|
+ group_data[group_id]["states"].append(state)
|
|
|
+ group_data[group_id]["actions"].append(action)
|
|
|
+ group_data[group_id]["advantages"].append(reward) # 简化优势计算
|
|
|
+
|
|
|
+ state = next_state
|
|
|
+
|
|
|
+ # 更新策略
|
|
|
+ grpo.update(group_data)
|
|
|
+```
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+#### **关键设计解释**
|
|
|
+1. **分组策略**
|
|
|
+ - 维护多个策略组(`self.policies`),每组独立与环境交互并收集数据。
|
|
|
+ - 通过组间优势的**相对比较**(如其他组的平均优势作为基线)调整更新幅度。
|
|
|
+
|
|
|
+2. **相对优势计算**
|
|
|
+ - 在损失函数中,使用组间相对优势替代传统绝对优势值,鼓励策略间的竞争或协作。
|
|
|
+
|
|
|
+3. **PPO 剪切机制**
|
|
|
+ - 保留 PPO 的剪切目标(`torch.clamp`),确保策略更新稳定。
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+#### **应用场景(假设)**
|
|
|
+- **多策略探索**:通过组间差异增强探索能力,避免局部最优。
|
|
|
+- **多智能体系统**:扩展为多智能体协作/竞争场景(如游戏 AI)。
|
|
|
+- **鲁棒性训练**:相对优势减少对奖励绝对值的敏感度。
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+#### **注意事项**
|
|
|
+- 上述代码为**假设性实现**,真实 GRPO 可能涉及更复杂的组间交互机制(如知识共享、动态分组)。
|
|
|
+- 实际应用需结合具体任务调整优势计算、分组策略等模块。
|
|
|
+
|
|
|
+如需准确实现,建议等待 DeepSeek 官方技术公开后参考其论文或代码库。
|
|
|
+
|
|
|
+
|
|
|
+# 大语言模型(LLM)训练与推理
|
|
|
+
|
|
|
+SFT GRPO
|
|
|
+## 基于GPU CUDA的训练与推理环境
|
|
|
+ python库: PyTorch+CUDA
|
|
|
+ 运行环境:Windows11 环境
|
|
|
+
|
|
|
+### 验证Pytorch是否支持CUDA
|
|
|
+ import torch
|
|
|
+
|
|
|
+ print(torch.__version__) # 查看 PyTorch 版本
|
|
|
+ # 检查 CUDA 是否可用
|
|
|
+ if torch.cuda.is_available():
|
|
|
+ print("CUDA 可用")
|
|
|
+ print("CUDA 版本:", torch.version.cuda)
|
|
|
+ print("GPU 名称:", torch.cuda.get_device_name(0))
|
|
|
+ else:
|
|
|
+ print("CUDA 不可用")
|
|
|
+
|
|
|
+
|
|
|
+### 安装NVIDIA CUDA Toolkit
|
|
|
+ 安装包下载链接: https://developer.nvidia.com/cuda-downloads
|
|
|
+ 命令:nvcc --version 验证是否安装成功
|
|
|
+ 安装成功信息示例:
|
|
|
+ nvcc: NVIDIA (R) Cuda compiler driver
|
|
|
+ Copyright (c) 2005-2023 NVIDIA Corporation
|
|
|
+ Built on ...
|
|
|
+ Cuda compilation tools, release 12.3, V12.3.107
|
|
|
+
|
|
|
+### 安装支持CUDA的Pytorch
|
|
|
+ 1. 卸载当前 PyTorch 执行命令:pip uninstall torch
|
|
|
+ 2. 生成安装支持CUDA的PyTorch命令,命令生成链接:https://pytorch.org/get-started/locally/
|
|
|
+ 如:pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
|
|
|
+
|
|
|
+# 大语言模型(LLM)服务器参数配置
|
|
|
+ 源自Deepseek-R1对话获取
|
|
|
+
|
|
|
+## Deepseek-R1 32B模型(或其他相同参数量规模)服务器配置评估
|
|
|
+
|
|
|
+为了支持训练或推理一个 **32B(320亿)参数** 的模型,服务器配置需要综合考虑计算能力、内存容量、存储速度和网络带宽。以下是推荐的服务器配置参数及数量:
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+### 1. **内存(RAM)需求**
|
|
|
+ - **模型参数**:32B参数,假设使用FP16(2字节/参数),内存占用约为:
|
|
|
+ 32 × 10^9 × 2 bytes = 64 { GB}
|
|
|
+ - **优化器状态**:对于Adam优化器,需要额外的2-3倍内存(约128-192 GB)。
|
|
|
+ - **激活值**:取决于批量大小和模型深度,可能额外需要64-256 GB。
|
|
|
+ - **推荐内存配置**:
|
|
|
+ - **大小**:至少 **256 GB**,推荐 **512 GB** 或更高。
|
|
|
+ - **速度**:DDR4-3200 或 DDR5-4800。
|
|
|
+ - **通道数**:至少4通道,推荐8通道以提高带宽。
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+### 2. **显卡(GPU)需求**
|
|
|
+ - **显存需求**:
|
|
|
+ - 单个GPU的显存需容纳模型分片、优化器状态和激活值。
|
|
|
+ - 对于32B模型,假设使用8张GPU,每张GPU需加载约8 GB参数(FP16)。
|
|
|
+ - 加上优化器状态和激活值,每张GPU显存需求约为 **24-48 GB**。
|
|
|
+ - **推荐显卡配置**:
|
|
|
+ - **型号**:NVIDIA A100(40 GB 或 80 GB)或 H100(80 GB)。
|
|
|
+ - **数量**:至少 **8 张**,推荐 **16 张** 以支持更大批量或更高并行度。
|
|
|
+ - **互联**:使用NVLink或InfiniBand确保高速通信。
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+### 3. **CPU需求**
|
|
|
+ - **核心数**:至少 **32 核**,推荐 **64 核** 或更高。
|
|
|
+ - **型号**:Intel Xeon Gold 6348 或 AMD EPYC 7742。
|
|
|
+ - **峰值性能**:支持高吞吐量和低延迟的数据预处理和任务调度。
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+### 4. **硬盘(存储)需求**
|
|
|
+ - **类型**:NVMe SSD,用于高速读写训练数据和检查点。
|
|
|
+ - **容量**:至少 **2 TB**,推荐 **4 TB** 或更高。
|
|
|
+ - **速度**:读写速度应达到 **3.5 GB/s** 或更高。
|
|
|
+ - **备份**:可额外配置大容量HDD(10 TB以上)用于数据备份。
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+### 5. **网络需求**
|
|
|
+ - **带宽**:至少 **10 GbE**,推荐 **100 GbE** 或 InfiniBand。
|
|
|
+ - **延迟**:低延迟网络(如InfiniBand)对分布式训练至关重要。
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+### 6. **推荐服务器配置**
|
|
|
+ - **单台服务器配置**:
|
|
|
+ - **CPU**:2x Intel Xeon Gold 6348(共64核)。
|
|
|
+ - **内存**:512 GB DDR4-3200(8通道)。
|
|
|
+ - **GPU**:8x NVIDIA A100 80 GB。
|
|
|
+ - **存储**:2x 2 TB NVMe SSD(RAID 0),1x 10 TB HDD。
|
|
|
+ - **网络**:100 GbE 或 InfiniBand HDR。
|
|
|
+ - **服务器数量**:
|
|
|
+ - 对于32B模型,1-2台服务器即可满足需求。
|
|
|
+ - 如果需要更高吞吐量或更大批量,可扩展至4台服务器。
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+### 7. **分布式训练配置**
|
|
|
+ - 如果使用多台服务器进行分布式训练:
|
|
|
+ - 每台服务器配置同上。
|
|
|
+ - 使用高速网络(如InfiniBand)连接多台服务器。
|
|
|
+ - 配置分布式文件系统(如Lustre或NFS)以共享数据和检查点。
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+### 8. **软件环境**
|
|
|
+ - **深度学习框架**:PyTorch、TensorFlow 或 JAX。
|
|
|
+ - **分布式训练库**:DeepSpeed、Megatron-LM 或 Horovod。
|
|
|
+ - **操作系统**:Ubuntu 20.04 LTS 或 CentOS 8。
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+### 总结
|
|
|
+对于32B参数的模型训练或推理,推荐以下配置:
|
|
|
+- **CPU**:64核(2x Intel Xeon Gold 6348)。
|
|
|
+- **内存**:512 GB DDR4-3200。
|
|
|
+- **GPU**:8-16x NVIDIA A100 80 GB。
|
|
|
+- **存储**:4 TB NVMe SSD + 10 TB HDD。
|
|
|
+- **网络**:100 GbE 或 InfiniBand。
|
|
|
+
|
|
|
+根据具体任务需求(如批量大小、训练速度),可以调整服务器数量或硬件配置。如果需要更详细的配置建议或优化方案,请提供更多任务细节!
|
|
|
+
|
|
|
+## Deepseek-R1 671B模型服务器配置评估
|
|
|
+
|
|
|
+### 训练模型服务器参数配置
|
|
|
+|组件|推荐配置|
|
|
|
+|:----:|:----:|
|
|
|
+|GPU|16 × NVIDIA A100 80GB(通过 NVLink 互联)|
|
|
|
+|CPU|2 × AMD EPYC 7763(64 核,128 线程)|
|
|
|
+|内存|2TB DDR4 ECC|
|
|
|
+|存储|20TB NVMe SSD(分布式文件系统,如 Lustre)|
|
|
|
+|网络|100GbE InfiniBand|
|
|
|
+|操作系统|Ubuntu 20.04 LTS|
|
|
|
+|深度学习框架|PyTorch 2.0+,DeepSpeed,Megatron-LM|
|
|
|
+
|
|
|
+### 推理(运行)模型服务器参数配置
|
|
|
+|组件|推荐配置|
|
|
|
+|:----:|:----:|
|
|
|
+|GPU|8 × NVIDIA A100 80GB(通过 NVLink 互联)|
|
|
|
+|CPU|2 × AMD EPYC 7763(64 核,128 线程)|
|
|
|
+|内存|2TB DDR4 ECC|
|
|
|
+|存储|20TB NVMe SSD(分布式文件系统,如 Lustre)|
|
|
|
+|网络|100GbE InfiniBand|
|
|
|
+|操作系统|Ubuntu 20.04 LTS|
|
|
|
+|深度学习框架|PyTorch 2.0+,DeepSpeed,Megatron-LM|
|
|
|
+
|
|
|
+估算:
|
|
|
+并发用户数:8 × A100 80GB的配置可以支持10-50个并发用户。
|
|
|
+每秒输出tokens数:每秒可以输出10-50个tokens。
|
|
|
+建议:
|
|
|
+如果需要支持更多并发用户或更高的token输出速度,可以增加GPU数量(如16 × A100 80GB)或使用更高效的推理框架优化(如FasterTransformer)。
|
|
|
+对于更高性能需求,可以考虑使用专门优化的推理硬件(如NVIDIA H100)或分布式推理集群
|
|
|
+
|
|
|
+# Deepseek-R1模型分布式训练及部署
|
|
|
+ 尚待服务器环境具备时验证
|
|
|
+
|
|
|
+以下是支持多节点和多 GPU 分布式训练的代码:
|
|
|
+```python
|
|
|
+# model_trainer_distribute.py
|
|
|
+import torch
|
|
|
+import torch.distributed as dist
|
|
|
+from torch.utils.data import Dataset, DataLoader
|
|
|
+from torch.nn.parallel import DistributedDataParallel as DDP
|
|
|
+from torch.utils.data.distributed import DistributedSampler
|
|
|
+from transformers import AutoTokenizer, AutoModelForCausalLM, AdamW
|
|
|
+from src.config import Config
|
|
|
+import logging
|
|
|
+import os
|
|
|
+
|
|
|
+logging.basicConfig(level=logging.INFO)
|
|
|
+logger = logging.getLogger(__name__)
|
|
|
+
|
|
|
+class TextDataset(Dataset):
|
|
|
+ """自定义数据集类"""
|
|
|
+ def __init__(self, file_path, tokenizer, seq_length):
|
|
|
+ self.tokenizer = tokenizer
|
|
|
+ self.seq_length = seq_length
|
|
|
+ with open(file_path, "r", encoding="utf-8") as f:
|
|
|
+ self.lines = f.read().splitlines()
|
|
|
+
|
|
|
+ def __len__(self):
|
|
|
+ return len(self.lines)
|
|
|
+
|
|
|
+ def __getitem__(self, idx):
|
|
|
+ line = self.lines[idx]
|
|
|
+ tokens = self.tokenizer.encode(
|
|
|
+ line,
|
|
|
+ max_length=self.seq_length,
|
|
|
+ truncation=True,
|
|
|
+ padding="max_length"
|
|
|
+ )
|
|
|
+ return torch.tensor(tokens) # 返回 CPU 上的张量
|
|
|
+
|
|
|
+class ModelTrainer:
|
|
|
+ def __init__(self, local_rank, world_size):
|
|
|
+ """初始化模型、分词器和优化器"""
|
|
|
+ self.local_rank = local_rank
|
|
|
+ self.world_size = world_size
|
|
|
+ self.device = torch.device(f"cuda:{local_rank}" if torch.cuda.is_available() else "cpu")
|
|
|
+ logger.info(f"Using device: {self.device}")
|
|
|
+
|
|
|
+ try:
|
|
|
+ # 加载分词器和模型
|
|
|
+ self.tokenizer = AutoTokenizer.from_pretrained(Config.PRETRAINED_MODEL_DIR)
|
|
|
+ self.model = AutoModelForCausalLM.from_pretrained(Config.PRETRAINED_MODEL_DIR)
|
|
|
+ self.model.to(self.device) # 将模型移动到设备
|
|
|
+
|
|
|
+ # 使用 DistributedDataParallel 包装模型
|
|
|
+ self.model = DDP(self.model, device_ids=[local_rank], output_device=local_rank)
|
|
|
+ logger.info("Pretrained model and tokenizer loaded.")
|
|
|
+ except Exception as e:
|
|
|
+ logger.error(f"Failed to load pretrained model: {e}")
|
|
|
+ raise
|
|
|
+
|
|
|
+ def train(self):
|
|
|
+ """训练模型"""
|
|
|
+ try:
|
|
|
+ # 加载数据集
|
|
|
+ dataset = TextDataset(Config.PROCESSED_DATA_PATH, self.tokenizer, Config.SEQ_LENGTH)
|
|
|
+ sampler = DistributedSampler(dataset, num_replicas=self.world_size, rank=self.local_rank)
|
|
|
+ dataloader = DataLoader(
|
|
|
+ dataset,
|
|
|
+ batch_size=Config.BATCH_SIZE,
|
|
|
+ sampler=sampler,
|
|
|
+ num_workers=4
|
|
|
+ )
|
|
|
+
|
|
|
+ # 初始化优化器
|
|
|
+ optimizer = AdamW(self.model.parameters(), lr=Config.LEARNING_RATE)
|
|
|
+
|
|
|
+ # 训练循环
|
|
|
+ self.model.train()
|
|
|
+ for epoch in range(Config.EPOCHS):
|
|
|
+ sampler.set_epoch(epoch) # 设置 epoch 以打乱数据
|
|
|
+ for batch in dataloader:
|
|
|
+ # 将输入数据移动到设备
|
|
|
+ inputs = batch.to(self.device)
|
|
|
+
|
|
|
+ # 前向传播
|
|
|
+ outputs = self.model(inputs, labels=inputs)
|
|
|
+ loss = outputs.loss
|
|
|
+
|
|
|
+ # 反向传播和优化
|
|
|
+ loss.backward()
|
|
|
+ optimizer.step()
|
|
|
+ optimizer.zero_grad()
|
|
|
+
|
|
|
+ if self.local_rank == 0: # 仅主进程记录日志
|
|
|
+ logger.info(f"Epoch {epoch + 1}/{Config.EPOCHS}, Loss: {loss.item()}")
|
|
|
+
|
|
|
+ # 保存训练后的模型(仅主进程保存)
|
|
|
+ if self.local_rank == 0:
|
|
|
+ os.makedirs(Config.TRAINED_MODEL_DIR, exist_ok=True)
|
|
|
+ self.model.module.save_pretrained(Config.TRAINED_MODEL_DIR)
|
|
|
+ self.tokenizer.save_pretrained(Config.TRAINED_MODEL_DIR)
|
|
|
+ logger.info(f"Model saved to {Config.TRAINED_MODEL_DIR}")
|
|
|
+
|
|
|
+ except Exception as e:
|
|
|
+ logger.error(f"Training failed: {e}")
|
|
|
+ raise
|
|
|
+
|
|
|
+def setup_distributed():
|
|
|
+ """初始化分布式训练环境"""
|
|
|
+ dist.init_process_group(backend="nccl")
|
|
|
+ local_rank = int(os.environ["LOCAL_RANK"])
|
|
|
+ world_size = int(os.environ["WORLD_SIZE"])
|
|
|
+ return local_rank, world_size
|
|
|
+
|
|
|
+def cleanup_distributed():
|
|
|
+ """清理分布式训练环境"""
|
|
|
+ dist.destroy_process_group()
|
|
|
+
|
|
|
+def main():
|
|
|
+ # 初始化分布式训练
|
|
|
+ local_rank, world_size = setup_distributed()
|
|
|
+
|
|
|
+ try:
|
|
|
+ # 初始化训练器
|
|
|
+ trainer = ModelTrainer(local_rank, world_size)
|
|
|
+ trainer.train()
|
|
|
+ finally:
|
|
|
+ # 清理分布式训练环境
|
|
|
+ cleanup_distributed()
|
|
|
+
|
|
|
+if __name__ == "__main__":
|
|
|
+ main()
|
|
|
+```
|
|
|
+
|
|
|
+部署方案
|
|
|
+1. 单服务器多 GPU 训练
|
|
|
+环境要求
|
|
|
+一台服务器,配备多张 GPU(如 4 张 NVIDIA A100)。
|
|
|
+安装 PyTorch 和 Transformers 库。
|
|
|
+启动命令
|
|
|
+使用 torchrun 启动分布式训练:
|
|
|
+
|
|
|
+```bash
|
|
|
+torchrun --nproc_per_node=4 --nnodes=1 --node_rank=0 --master_addr=localhost --master_port=12345 model_trainer.py
|
|
|
+```
|
|
|
+
|
|
|
+参数说明
|
|
|
+--nproc_per_node:每个节点的 GPU 数量。
|
|
|
+--nnodes:节点总数(单节点为 1)。
|
|
|
+--node_rank:当前节点的 rank(单节点为 0)。
|
|
|
+--master_addr 和 --master_port:主节点的地址和端口。
|
|
|
+
|
|
|
+2. 多服务器多 GPU 训练
|
|
|
+环境要求
|
|
|
+多台服务器,每台服务器配备多张 GPU。
|
|
|
+所有服务器之间可以通过网络互相访问。
|
|
|
+安装 PyTorch 和 Transformers 库。
|
|
|
+
|
|
|
+启动命令
|
|
|
+假设有 2 台服务器,每台服务器有 4 张 GPU。
|
|
|
+
|
|
|
+主节点(Node 0)
|
|
|
+
|
|
|
+```bash
|
|
|
+torchrun \
|
|
|
+ --nproc_per_node=4 \
|
|
|
+ --nnodes=2 \
|
|
|
+ --node_rank=0 \
|
|
|
+ --master_addr=<主节点IP> \
|
|
|
+ --master_port=12345 \
|
|
|
+ model_trainer.py
|
|
|
+```
|
|
|
+
|
|
|
+从节点(Node 1)
|
|
|
+
|
|
|
+```bash
|
|
|
+torchrun \
|
|
|
+ --nproc_per_node=4 \
|
|
|
+ --nnodes=2 \
|
|
|
+ --node_rank=1 \
|
|
|
+ --master_addr=<主节点IP> \
|
|
|
+ --master_port=12345 \
|
|
|
+ model_trainer.py
|
|
|
+```
|
|
|
+
|
|
|
+参数说明
|
|
|
+--nproc_per_node:每个节点的 GPU 数量。
|
|
|
+--nnodes:节点总数。
|
|
|
+--node_rank:当前节点的 rank(主节点为 0,从节点为 1)。
|
|
|
+--master_addr:主节点的 IP 地址。
|
|
|
+--master_port:主节点的端口。
|
|
|
+
|
|
|
+执行训练方法
|
|
|
+1. 单服务器多 GPU 训练
|
|
|
+确保所有 GPU 可用:
|
|
|
+```bash
|
|
|
+nvidia-smi
|
|
|
+```
|
|
|
+
|
|
|
+启动训练:
|
|
|
+
|
|
|
+```bash
|
|
|
+torchrun --nproc_per_node=4 --nnodes=1 --node_rank=0 --master_addr=localhost --master_port=12345 model_trainer.py
|
|
|
+```
|
|
|
+
|
|
|
+2. 多服务器多 GPU 训练
|
|
|
+在主节点和从节点上分别启动训练:
|
|
|
+
|
|
|
+主节点:
|
|
|
+```bash
|
|
|
+torchrun --nproc_per_node=4 --nnodes=2 --node_rank=0 --master_addr=<主节点IP> --master_port=12345 model_trainer.py
|
|
|
+```
|
|
|
+
|
|
|
+从节点:
|
|
|
+```bash
|
|
|
+torchrun --nproc_per_node=4 --nnodes=2 --node_rank=1 --master_addr=<主节点IP> --master_port=12345 model_trainer.py
|
|
|
+```
|
|
|
+确保所有节点可以互相访问,并且端口 12345 未被占用。
|
|
|
+
|
|
|
+总结
|
|
|
+通过上述重构和部署方案,代码可以支持:
|
|
|
+单服务器多 GPU 的分布式训练。
|
|
|
+多服务器多 GPU 的分布式训练。
|
|
|
+
|
|
|
+关键点:
|
|
|
+使用 DistributedDataParallel 实现模型并行。
|
|
|
+使用 DistributedSampler 实现数据并行。
|
|
|
+使用 torchrun 启动分布式训练。
|
|
|
+
|
|
|
+# Deepseek-R1 华为昇腾910B NPU训练方案
|
|
|
+
|
|
|
+在昇腾910B NPU上训练DeepSeek-R1 671B模型,需要结合昇腾AI处理器(如Ascend 910B)的硬件特性和华为的AI软件栈(如MindSpore)进行适配和优化。以下是详细的步骤和注意事项:
|
|
|
+
|
|
|
+1. 准备工作
|
|
|
+硬件环境
|
|
|
+昇腾910B NPU:确保你有可用的昇腾910B硬件环境(如Atlas 800训练服务器)。
|
|
|
+多机多卡配置:对于671B规模的模型,通常需要多机多卡(如多台Atlas 800服务器)进行分布式训练。
|
|
|
+
|
|
|
+软件环境
|
|
|
+操作系统:支持Ascend 910B的操作系统(如Ubuntu 18.04/20.04或CentOS 7.6)。
|
|
|
+驱动和固件:安装昇腾910B的驱动和固件。
|
|
|
+MindSpore:华为的深度学习框架,支持昇腾910B。
|
|
|
+安装MindSpore(推荐使用与Ascend 910B兼容的版本,如MindSpore 2.0+)。
|
|
|
+
|
|
|
+安装命令示例:
|
|
|
+```bash
|
|
|
+pip install mindspore-ascend
|
|
|
+```
|
|
|
+
|
|
|
+CANN:华为的异构计算架构,用于优化昇腾NPU的性能。
|
|
|
+安装CANN工具包(与MindSpore版本匹配)。
|
|
|
+
|
|
|
+数据集
|
|
|
+准备训练DeepSeek-R1 671B所需的数据集,并确保数据格式与MindSpore兼容。
|
|
|
+
|
|
|
+2. 模型适配
|
|
|
+模型转换
|
|
|
+如果DeepSeek-R1 671B模型是基于PyTorch或TensorFlow实现的,需要将其转换为MindSpore格式。
|
|
|
+使用MindSpore的模型转换工具(如mindconverter)将模型转换为MindSpore支持的格式。
|
|
|
+
|
|
|
+分布式训练支持
|
|
|
+DeepSeek-R1 671B模型规模巨大,通常需要分布式训练。
|
|
|
+使用MindSpore的分布式训练功能(如mindspore.set_auto_parallel_context)配置多机多卡训练。
|
|
|
+
|
|
|
+示例代码:
|
|
|
+```python
|
|
|
+import mindspore as ms
|
|
|
+from mindspore import context
|
|
|
+from mindspore.communication import init
|
|
|
+
|
|
|
+# 设置运行模式为图模式
|
|
|
+context.set_context(mode=context.GRAPH_MODE, device_target="Ascend")
|
|
|
+
|
|
|
+# 初始化分布式训练
|
|
|
+init()
|
|
|
+ms.set_auto_parallel_context(parallel_mode=ms.ParallelMode.SEMI_AUTO_PARALLEL, device_num=8)
|
|
|
+```
|
|
|
+
|
|
|
+混合精度训练
|
|
|
+为了提升训练效率,可以使用混合精度训练(FP16)。
|
|
|
+在MindSpore中启用混合精度:
|
|
|
+```python
|
|
|
+from mindspore import amp
|
|
|
+
|
|
|
+# 设置混合精度
|
|
|
+model = amp.build_train_network(model, optimizer, loss_fn, level="O2")
|
|
|
+```
|
|
|
+
|
|
|
+3. 训练流程
|
|
|
+数据加载
|
|
|
+使用MindSpore的Dataset API加载数据集。
|
|
|
+
|
|
|
+示例代码:
|
|
|
+```python
|
|
|
+from mindspore.dataset import GeneratorDataset
|
|
|
+
|
|
|
+dataset = GeneratorDataset(source=data_generator, column_names=["data", "label"])
|
|
|
+dataset = dataset.batch(batch_size=32)
|
|
|
+```
|
|
|
+
|
|
|
+模型定义
|
|
|
+使用MindSpore定义DeepSeek-R1 671B模型。
|
|
|
+示例代码:
|
|
|
+
|
|
|
+```python
|
|
|
+import mindspore.nn as nn
|
|
|
+
|
|
|
+class DeepSeekR1(nn.Cell):
|
|
|
+ def __init__(self):
|
|
|
+ super(DeepSeekR1, self).__init__()
|
|
|
+ # 定义模型结构
|
|
|
+ self.layer1 = nn.Dense(1024, 2048)
|
|
|
+ self.layer2 = nn.Dense(2048, 4096)
|
|
|
+ # 添加更多层...
|
|
|
+
|
|
|
+ def construct(self, x):
|
|
|
+ x = self.layer1(x)
|
|
|
+ x = self.layer2(x)
|
|
|
+ # 添加更多操作...
|
|
|
+ return x
|
|
|
+```
|
|
|
+
|
|
|
+损失函数和优化器
|
|
|
+定义损失函数和优化器。
|
|
|
+示例代码:
|
|
|
+
|
|
|
+```python
|
|
|
+from mindspore import nn
|
|
|
+
|
|
|
+# 定义损失函数
|
|
|
+loss_fn = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction="mean")
|
|
|
+
|
|
|
+# 定义优化器
|
|
|
+optimizer = nn.Adam(params=model.trainable_params(), learning_rate=0.001)
|
|
|
+```
|
|
|
+
|
|
|
+训练循环
|
|
|
+使用MindSpore的Model API进行训练。
|
|
|
+示例代码:
|
|
|
+
|
|
|
+```python
|
|
|
+from mindspore import Model
|
|
|
+
|
|
|
+# 创建模型
|
|
|
+model = Model(network=DeepSeekR1(), loss_fn=loss_fn, optimizer=optimizer)
|
|
|
+
|
|
|
+# 开始训练
|
|
|
+model.train(epoch=10, train_dataset=dataset)
|
|
|
+```
|
|
|
+
|
|
|
+4. 性能优化
|
|
|
+数据并行与模型并行
|
|
|
+对于671B规模的模型,通常需要结合数据并行和模型并行。
|
|
|
+使用MindSpore的set_auto_parallel_context配置并行策略:
|
|
|
+
|
|
|
+```python
|
|
|
+ms.set_auto_parallel_context(parallel_mode=ms.ParallelMode.AUTO_PARALLEL,
|
|
|
+ device_num=8,
|
|
|
+ full_batch=True,
|
|
|
+ gradient_aggregation_group=4)
|
|
|
+```
|
|
|
+
|
|
|
+内存优化
|
|
|
+使用MindSpore的内存优化功能(如grad_accumulation)减少显存占用。
|
|
|
+示例代码:
|
|
|
+
|
|
|
+```python
|
|
|
+ms.set_auto_parallel_context(grad_accumulation_step=4)
|
|
|
+```
|
|
|
+
|
|
|
+通信优化
|
|
|
+使用华为的HCCL(Huawei Collective Communication Library)优化多机多卡通信。
|
|
|
+确保网络带宽和延迟满足分布式训练的需求。
|
|
|
+
|
|
|
+5. 调试与监控
|
|
|
+日志记录
|
|
|
+使用MindSpore的日志功能记录训练过程。
|
|
|
+示例代码:
|
|
|
+
|
|
|
+```python
|
|
|
+import logging
|
|
|
+logging.basicConfig(level=logging.INFO)
|
|
|
+```
|
|
|
+
|
|
|
+性能监控
|
|
|
+使用华为的Ascend工具(如Ascend Performance Analyzer)监控训练性能。
|
|
|
+分析瓶颈(如计算、通信、I/O)并进行优化。
|
|
|
+
|
|
|
+6. 部署与推理
|
|
|
+训练完成后,使用MindSpore的export功能将模型导出为MindIR格式。
|
|
|
+在昇腾910B NPU上进行推理部署。
|
|
|
+
|
|
|
+注意事项
|
|
|
+硬件资源:671B规模的模型需要大量计算资源,确保硬件环境足够。
|
|
|
+分布式训练:多机多卡训练需要良好的网络环境和通信优化。
|
|
|
+版本兼容性:确保MindSpore、CANN和驱动版本兼容。
|
|
|
+文档支持:参考华为官方文档(如MindSpore和Ascend文档)获取最新信息。
|
|
|
+
|
|
|
+通过以上步骤,你可以在昇腾910B NPU上成功训练DeepSeek-R1 671B模型。如果遇到问题,可以联系华为技术支持或社区获取帮助。
|
|
|
+
|
|
|
# 应用Unsloth方案训练大模型
|
|
|
|
|
|
## 安装依赖包
|
|
|
+
|
|
|
1. pip install xformers
|
|
|
-2. pip install torch torchvision torchaudio triton
|
|
|
-3. 获取pytorch+CUDA 依赖包命令:https://pytorch.org/get-started/locally/ 命令示例:pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
|
|
|
-4. pip install unsloth datasets
|
|
|
-5. Windows环境 ,通过https://huggingface.co/madbuda/triton-windows-builds/tree/main 获取依赖triton包的whl文件安装
|
|
|
- Linux环境,支持pip install triton的安装
|
|
|
-6.
|
|
|
+2. 获取pytorch+CUDA 依赖包命令:https://pytorch.org/get-started/locally/ 命令示例:pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
|
|
|
+3. pip install unsloth datasets
|
|
|
+4. triton包安装
|
|
|
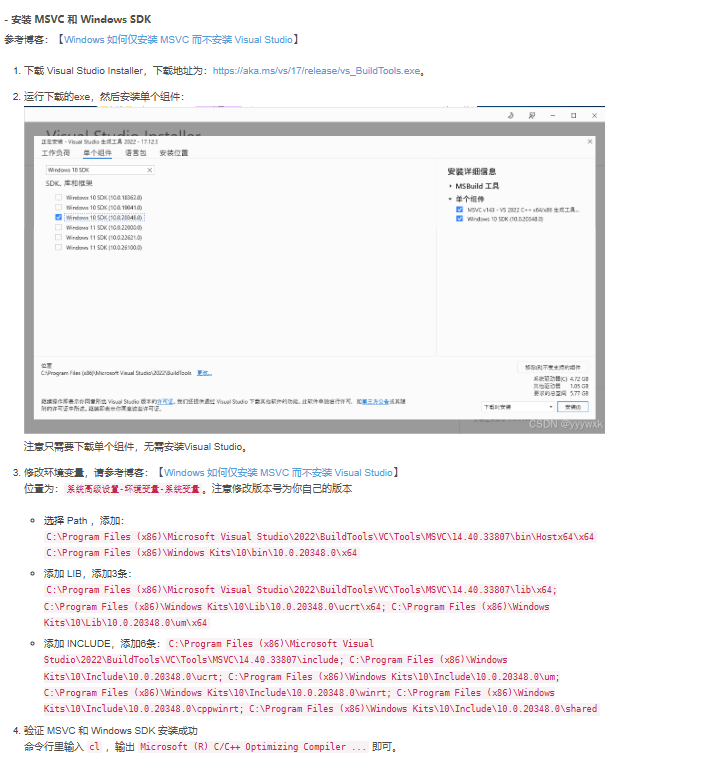
+ **Windows环境**
|
|
|
+ 通过https://huggingface.co/madbuda/triton-windows-builds/tree/main 获取依赖triton包的whl文件安装
|
|
|
+ <div align=center><img src="./resources/images/VS_BuildTools_Setup_Config_For_Windows.png"></div>
|
|
|
+
|
|
|
+ **Linux环境**
|
|
|
+ 支持pip install triton的安装
|
|
|
+
|
|
|
+5. pip install scikit-learn
|
|
|
+
|

 zhouyang.xie
zhouyang.xie
{kind=link}
{kind=link}